论文阅读笔记
论文信息
- 标题: Black-Box Prompt Optimization: Aligning Large Language Models without Model Training
- 作者: Jiale Cheng1,2* , Xiao Liu3,2* , Kehan Zheng1 , Pei Ke1 , Hongning Wang1 , Yuxiao Dong3 , Jie Tang3 , Minlie Huang1†
- 发表时间: 2024年8月
- 期刊/会议: ACL 2024 长论文
摘要
Large language models (LLMs) have shown impressive success in various applications. However, these models are often not well aligned with human intents, which calls for additional treatments on them; that is, the alignment problem. To make LLMs better follow user instructions, existing alignment methods primarily focus on further training them. However, the extra training of LLMs is usually expensive in terms of GPU computing; even worse, some LLMs are not accessible for userdemanded training, such as GPTs. In this work, we take a different perspective—Black-Box Prompt Optimization (BPO)—to perform alignments. The idea is to optimize user prompts to suit LLMs’ input understanding, so as to best realize users’ intents without updating LLMs’ parameters. BPO leverages human preferences to optimize prompts, thus making it superior to LLM (e.g., ChatGPT) as a prompt engineer. Moreover, BPO is model-agnostic, and the empirical results demonstrate that the BPOaligned ChatGPT yields a 22% increase in the win rate against its original version and 10% for GPT-4. Notably, the BPO-aligned LLMs can outperform the same models aligned by PPO and DPO, and it also brings additional performance gains when combining BPO with PPO or DPO. Code and datasets are released at https://github.com/thu-coai/BPO.
大语言模型(LLMs)在各种各样的应用中已经展现了令人瞩目的成功。然而,这些模型通常没有很好地对齐人类指示,这通常需要额外的处理手段;这就是对齐问题。为了使大模型更好地适合地遵循人类指令,现有的对齐方法主要关注如何进一步训练它们。然而,额外的 LLM 的训练通常需要大量的 GPU 计算资源,甚至更糟糕的是,某些 LLM 模型可能无法被用户需要的那样做训练 如 GPT。在此工作,我们采取一种不同的视角——黑盒提示词优化(BPO),来执行对齐。想法是,通过优化用户提示,来使 LLMs 的输入理解更适合,从而实现用户意图的最优化,而不需要更新 LLMs 的参数。BPO 利用人的偏好来优化提示,因此使其优于 LLM(如 ChatGPT),后者作为提示词工程师。此外,BPO 是模型无关的,经验结果表明BPO对齐后的ChatGPT可以对比原来的版本获得22%的提升,而对齐后的GPT-4可以获得10%的提升。令人瞩目的是,BPO对齐的 LLMs 可以与使用 PPO 和 DPO 对齐的相同模型相比获得额外的性能提升,并且当把BPO 和 PPO 或 DPO 结合时,BPO 还能获得额外的性能提升。代码和数据集可以在 https://github.com/thu-coai/BPO 中找到。
主要内容
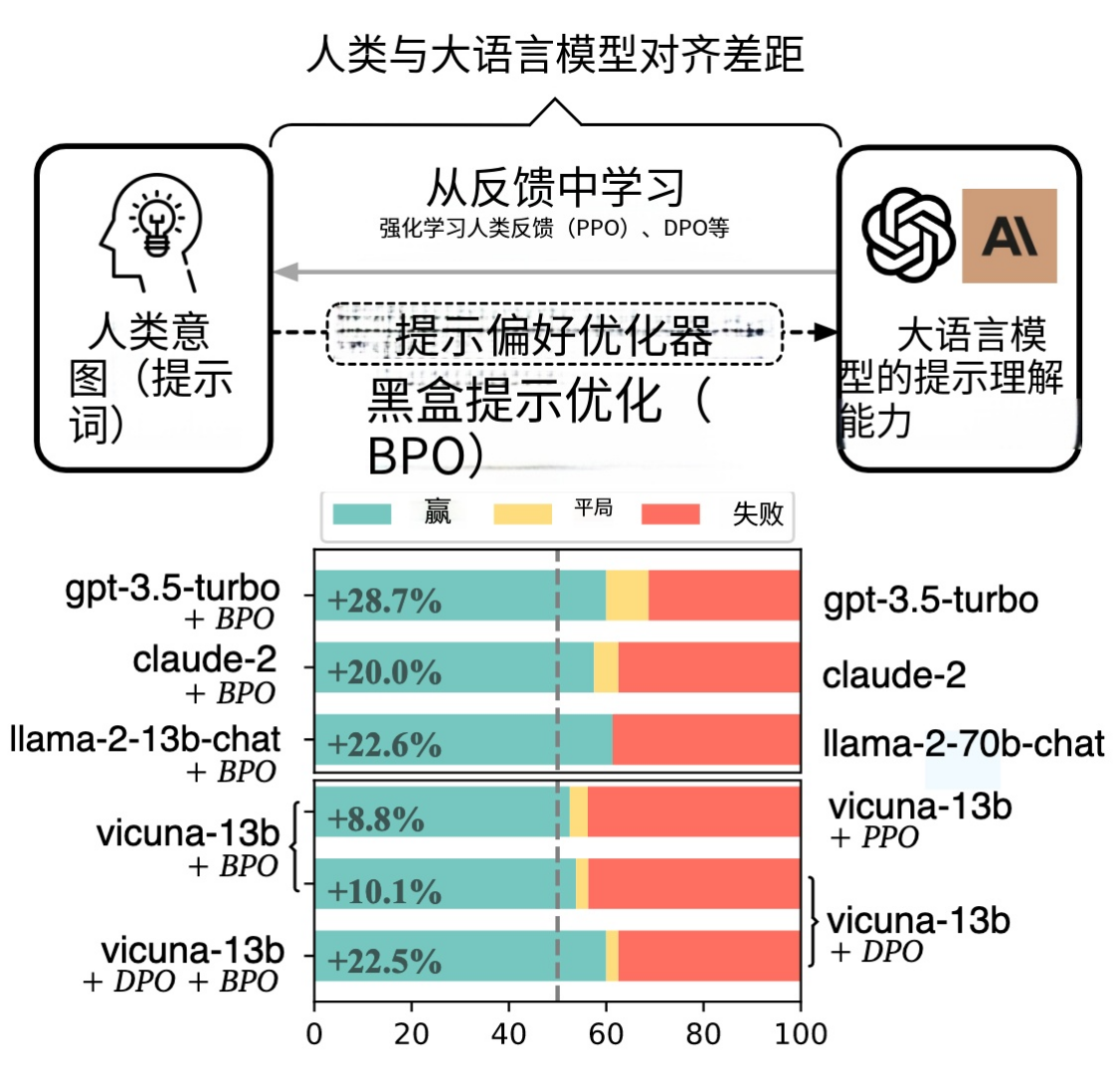
1. 研究背景
大型语言模型(LLMs)在各类应用中表现出色,但常存在与人类意图不一致的对齐问题。现有对齐方法(如 RLHF、DPO)需对模型进行额外训练,存在 GPU 计算成本高、闭源模型(如 GPTs)无法适配、可解释性差等缺陷,因此需要一种无需训练模型即可实现对齐的新方案。
2. 核心方法
提出黑盒提示优化(BPO),核心思路是优化用户提示以适配 LLMs 的输入理解,而非更新模型参数:
- 数据构建:收集 4 个含人类 / AI 偏好标注的数据集,筛选后得到 14K 样本(含原始提示、优质响应、劣质响应);
- 提示优化:利用 LLM 分析优劣响应差异,将关键特征融入原始提示,生成优化后提示,构建 “原始 - 优化” 提示对;
- 模型训练:基于提示对训练 seq2seq 模型(以 llama2-7b-chat 为骨干),实现自动提示优化,且 BPO 具备模型无关性和任务无关性。
3. 主要贡献
- 提出全新对齐范式:无需训练 LLMs,通过优化提示实现对齐,适用于 API 调用型和开源型模型;
- 性能优势显著:在多种模型上表现优于 PPO、DPO,且与二者结合可带来额外性能提升;
- 高可解释性:从解释生成、提示细化、提供提示、安全增强四方面优化提示,优化逻辑可追溯;
- 多功能性:可提升模型对齐效果、增强 SFT 数据质量、支持迭代式提示优化。
4. 实验结果
- 黑盒模型对齐:GPT-3.5-turbo、Claude-2 等模型的胜率提升 8.8%-22.0%,GPT-4 提升 10.1%;
- 模型缩放潜力:BPO 优化后的 llama2-13b-chat 可超越未优化的 llama2-70b-chat;
- 与 RLHF 结合:BPO+DPO 使 Vicuna 系列模型胜率提升超 29%,显著优于单独使用 PPO/DPO;
- 数据增强:用 BPO 优化的 Alpaca 数据集训练 LLMs,llama-13b 模型胜率较原始数据集提升 53.8%;
- 迭代优化:经 4 轮迭代优化后提示效果显著提升,且能保留优质原始提示的核心意图。
5. 个人思考
- 他们提出来的优化提示词的方法感觉是简单易行的,而且看起来也能够进一步优化新的提示词的方法;
- 他们做了大量的实验,很多工作都是在这里,看来我这边的也是需要堆时间做实验;
- 在特定任务上的结果他其实没有给出,还是给出的综合数据集上的结果;
- 原始提示词不是他们设计或者给出的,而是数据集里本身有的。
全文翻译(先做的全文翻译)
1. 介绍 (2025年12月27日 21:20-22:04)
最近,自然语言处理领域出现了令人瞩目的进步,这主要归功于大语言模型的的优势。在经过人工微调以后,这些模型展现了强大的指令执行和人类偏好理解能力,产生了向ChatGPT这些吸引众多关注的产品。
然而,把LLMs和人类偏好对齐不是轻而易举。主要困难在于,将人类意图(通过提示)与LLMs的输入理解之间的差距缩小。已经有令人瞩目的努力关注在让LLMs靠近人类偏好上,包括来自人类反馈的强化学习(RLHF) (Ouyang et al., 2022),来自AI反馈的强化学习(RLAIF)(Bai et al., 2022b; Lee et al., 2023),或者直接偏好优化(DPO)(Rafailov et al., 2023)。尽管如此,这些方法存在各种不足:
- 效率性:随着LLMs变得更大了,训练这些模型变得更加昂贵和困难,尤其是当使用臭名昭著的不那么稳定的RL算法来完成这个目的时。
- 可及性:几乎所有表现最好的大模型,比如GPT(OpenAI, 2023)和Claude2(Anthropic, 2023a),都是b闭源的,只能通过API访问。因此,这些基于训练的方法不适用于这些不在组织的用户去提升模型对齐能力。
- 可解释性:在使用这些方法的时候,这些人类偏好的建模和精确的结论都是不可解释的。
与前面提到的对齐方法不同,我们提出引导人类提示以适应LLMs理解。虽然这个想法与“提示工程”密切相关,但它的自动化原型可以追溯到AutoPrompt(Shin等人,2020)和提示调优(即P-Tuning)(Liu等人,2021;Lester等人,2021),其中优化提示词以提高任务表现同时不需要训练模型。我们的新对齐方法,黑盒提示优化(BPO),提出了一种高效和可解释的范例,无需修改这些模型就可以对大模型进行对齐。BPO背后的中心思想是创建一个自动提示词优化器,它将人书写的提示词——这些提示通常组织得较少或不明确——改写为更好地传递人类意图的提示词。因此,这些提示词将会对LLM更加友好,并产生更好的人类便好的响应。
在BPO中,提示词偏好优化器是从偏好比较中学习的。我们整理了一个公开可用的SFT数据集的子集,里面的样本中包含人类偏好或者是人工智能偏好。我们的训练数据的每个实例都包含一个提示以及一对喜欢和不喜欢的响应。我们随后利用大语言模型(LLMs)来界定并分析评价成对回复的差异,接着让大语言模型优化输入提示,以明确纳入那些能将回复从“不利”转向“有利”的特征。通过这种方式,我们构建了1.4万组“原始指令-优化后指令”配对数据,用以训练一个序列到序列(sequence-to-sequence)模型——该模型可对用户指令进行优化。
我们的广泛实验表明:无需额外训练大语言模型(LLM),BPO即可显著提升基于API的LLM与开源LLM的对齐效果——在gpt-3.5-turbo、gpt-4、claude-2、llama-2-chat、vicuna等模型上,胜率提升幅度达8.8%至22.0%。
此外,我们证明:BPO不仅性能优于基于PPO(Schulman等,2017)和DPO(Rafailov等,2023)的RLHF,还能在这些RLHF训练之后进一步提升LLM的对齐效果。我们还发现,在Alpaca数据集的监督微调实验中,BPO可通过优化回复质量来对齐LLM。另外,我们已证实:相较于直接将LLM用作提示工程师(prompt engineer),BPO更具优势——这凸显了融入人类反馈的重要性。
我们的贡献可总结如下:
- 我们提出了一种新颖的提示优化方法BPO,该方法无需训练大语言模型(LLM)即可增强其与人偏好的对齐效果,并在包括基于API的模型与开源模型在内的多种LLM上展现出性能提升。
- 我们通过实验验证:除了现有的RLHF(基于人类反馈的强化学习)与偏好学习方法外,BPO是一种新颖且具有竞争力的对齐方法——在大量实验中,其性能优于PPO与DPO。此外,我们还证明:BPO与RLHF的对齐机制正交(即互不干扰、可独立叠加),能在传统对齐流程的基础上进一步带来额外增益。
- 我们从提示词解释、澄清、丰富及安全性增强四个维度,系统分析了BPO如何优化原始提示;同时证明:在对齐大语言模型(LLM)时,BPO相较于现有偏好学习算法具有更好的可解释性。
2. 相关工作
在大规模语料上预训练的大型语言模型(LLMs)能够生成流畅的文本,但在遵循用户指令方面尚未很好地对齐。因此,使大语言模型与人类意图保持一致已成为一个重要的研究问题。现有的对齐方法大多遵循Ouyang等人(2022)提出的范式,主要包括两个阶段:监督微调(SFT)和基于人类反馈的强化学习(RLHF)。
监督微调(SFT)。SFT对齐赋予大型语言模型初步的指令跟随能力。然而,它严重依赖于大量高质量的微调数据。由于人工编写数据的成本高昂,基于少量人工构建的种子集进行自我指导式数据增强(Wang等,2022)已成为学术界的主流方法(Taori等,2023;BELLEGroup,2023)。尽管如此,SFT对齐仍存在幻觉问题、可扩展性不足以及对人类偏好理解较差等缺陷。
基于人类反馈的强化学习(RLHF)。RLHF对齐旨在进一步使大型语言模型与可扩展的反馈保持一致。其标准框架(Stiennon等,2020;Ouyang等,2022)包括奖励建模与策略训练两个阶段。由于人工标注成本较高(Ouyang等,2022;Ji等,2024b),一些研究开始探索引入人工智能反馈,并取得了令人瞩目的成果(Bai等,2022b;Lee等,2023)。此外,考虑到RLHF流程繁琐且强化学习训练不稳定,部分工作尝试采用其他方法来从偏好反馈中学习。Rafailov等人(2023)将反馈机制引入损失函数的设计中。进一步地,也有研究探索自我改进(Yuan等,2024;Xu等,2024)以及智能体之间的对齐(Lai等,2024)。
提示工程与提示调优。自预训练语言模型提出以来,利用提示调优来完成自然语言处理任务逐渐成为一种新的范式(Brown等,2020a;Liu等,2021)。提示调优主要分为两种类型:硬提示调优与软提示调优。硬提示调优,亦称提示工程,通常需要大量的人工投入。因此,许多研究致力于探索如何自动化这一过程,其起源可追溯至AutoPrompt(Shin等,2020)。近年来,随着大型语言模型的出现,利用语言模型进行自动化提示工程展现出卓越的性能(Zhou等,2022;Yang等,2023;Pryzant等,2023;Pan等,2023;Li等,2024)。然而,现有方法主要聚焦于特定任务而非模型对齐,并且需要为每个任务单独搜索合适的提示。此外,这些方法通常需针对单一模型进行优化,因而无法在所有模型中通用,这进一步限制了它们的适用性。软提示调优(Liu等,2021;Lester等,2021;Li和Liang,2021)通过在嵌入空间中进行优化,而非局限于固定的词表,从而进一步提升了效果,但它需要对模型参数进行调优,灵活性不如硬提示调优。
提示调优与模型训练一直是提升预训练模型性能的两个并行路径。目前的模型对齐策略主要侧重于调整模型以遵循用户意图和指令,而鲜有研究探索即插即用的对齐工具(Ji等,2024a)。在大型语言模型的背景下,模型规模已变得非常庞大,训练甚至获取(例如基于API的模型)都十分困难。因此,我们认为提示优化值得引起重视,并且在不修改大型语言模型本身的前提下,仅通过优化输入提示即可实现模型对齐。
3 黑盒提示词优化(BPO)(2025年12月27日 23:00-00:58)
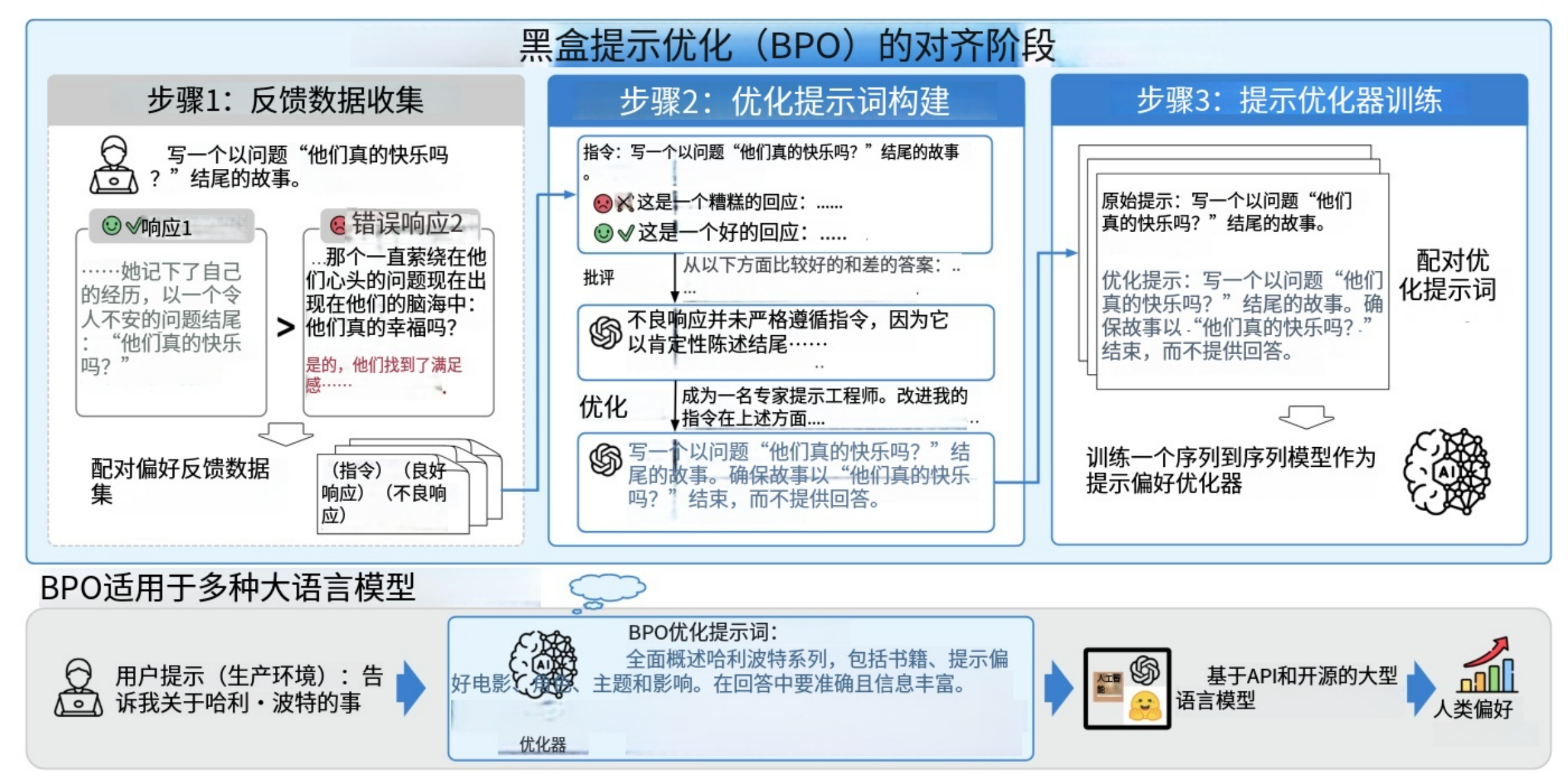 图2:BPO(黑盒提示优化)包含三个主要步骤:收集反馈数据(我们采用开源的反馈数据)、基于反馈数据构建提示优化对,以及利用这些提示对训练一个提示优化模型。通过这种方式,BPO充当了人类与AI之间的“翻译器”,将人类的提示优化为更适配AI生成的形式,从而获得更符合人类偏好的响应,同时将模型本身视为黑盒。
图2:BPO(黑盒提示优化)包含三个主要步骤:收集反馈数据(我们采用开源的反馈数据)、基于反馈数据构建提示优化对,以及利用这些提示对训练一个提示优化模型。通过这种方式,BPO充当了人类与AI之间的“翻译器”,将人类的提示优化为更适配AI生成的形式,从而获得更符合人类偏好的响应,同时将模型本身视为黑盒。
BPO的整体流程如图2所示。BPO旨在通过优化输入提示来增强模型输出与人类偏好之间的一致性。为此,我们首先收集若干带有人类偏好标注的指令微调数据集,并对数据进行细致整理与低质量样本过滤。随后,我们利用大语言模型(LLM)捕捉人类偏好与不偏好响应之间的差异,并基于此差异使用LLM对输入进行优化。由此,我们得到一组原始指令及其改进后的版本,并进一步训练一个序列到序列(sequence-to-sequence)模型,以实现对用户输入的自动优化。
3.1 任务定义
如上所述,我们的任务是优化用户输入,以帮助大语言模型(LLMs)生成更好的回复。形式上,我们将用户输入表示为 X_user。我们的目标是构建一个函数 F,将 X_user 映射到其优化版本,记为 X_opt。为此,我们引入了带注释的人类偏好数据,其中偏好的回复代表良好的模型输出,而另一个则代表较差的输出。通过捕捉这些偏好数据之间的差异,我们可以将人类偏好的属性融入到用户指令中,使其更符合大语言模型的能力范围,从而使大语言模型的输出更好地与人类偏好保持一致。受近期利用大语言模型作为评估器的工作启发(Wang et al., 2023; Zheng et al., 2023),我们认为大语言模型具备理解各种回复中不同特征的能力。因此,我们利用大语言模型来获取 X_opt。具体而言,每个样本表示为 (X_user, Y_good, Y_bad),其中 Y_good 代表偏好的回复,Y_bad 代表不偏好的回复。因此,基于大语言模型的提示优化过程可表示为 X_opt = LLM(X_user, Y_good, Y_bad)。最后,我们通过在 (X_user, X_opt) 对上训练一个较小的序列到序列(seq2seq)模型来构建 F 函数。
3.2 训练数据构造
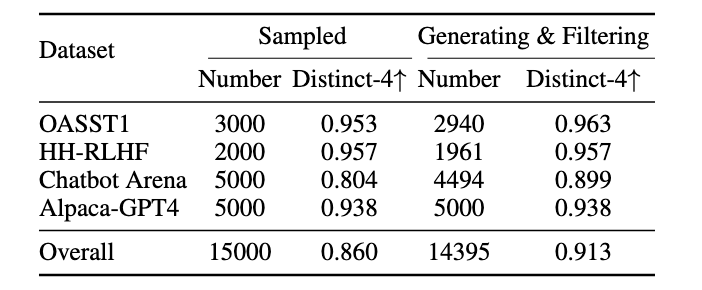 表1:偏好数据统计。我们从开源提示数据集中采样提示,并通过筛选形成偏好训练数据集。
表1:偏好数据统计。我们从开源提示数据集中采样提示,并通过筛选形成偏好训练数据集。
为构建优化后的提示(prompt),我们首先收集带有人类偏好标注的数据集。总体而言,我们使用了4个带有人类偏好标注的指令微调数据集(具体见表1)。这些数据集的详细描述见附录A。
在收集并重新格式化这些数据集后,我们通过人工设计的规则(例如,过短的指令往往质量较低)仔细剔除低质量实例,并利用**自BLEU(self-BLEU)**进行严格的多样性过滤。最终,我们得到了14,000条多样化的样本,格式均为 (X_user, Y_good, Y_bad)(用户输入、偏好回复、非偏好回复)。
在本研究中,我们主要关注单轮回复生成任务,多轮对话场景将留待未来工作探索。
随后,我们利用ChatGPT(OpenAI, 2022)对这些指令进行优化。经过细致的提示工程(prompt engineering)调整后,我们针对不同的数据格式采用了两类提示(具体示例见附录B)。接下来,我们通过基于规则的方法进行质量过滤,剔除错误的优化结果(例如,格式错误的内容)。
完成上述全流程后,我们的数据集包含约14,000对优化前后的指令,最终分布如表1所示。总体 distinct 分数(Li et al., 2016)表明我们的数据集具有高度多样性。
3.3 模型训练
基于构建的数据集,我们学习了一个小型**序列到序列(sequence-to-sequence, seq2seq)**模型,以实现对用户指令的自动优化。形式化地,我们在给定输入 X_user的条件下生成优化后的输入 X_opt,其损失函数定义如下:
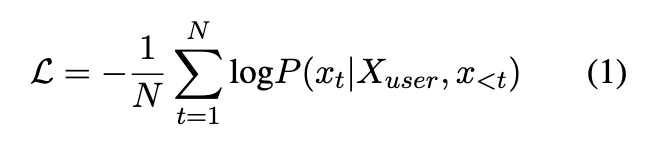 公式1
公式1
其中,$N$ 为 $X_{\text{opt}}$ 的长度,$x_t$ 表示 $X_{\text{opt}}$ 中的第 $t$ 个token。在本研究中,我们选择以 llama2-7b-chat 作为骨干模型——因为我们相信,更强的模型能更好地学习 $X_{\text{user}}$ 与 $X_{\text{opt}}$ 之间的隐式偏好映射(implicit preference mapping)。
与此同时,7B参数规模的模型在大语言模型(LLMs)中属于参数量较小的类别,这使其在训练和推理阶段更具效率。关于模型规模扩展的探索,我们将留待未来工作。
3.4 和现存的方法进行比较
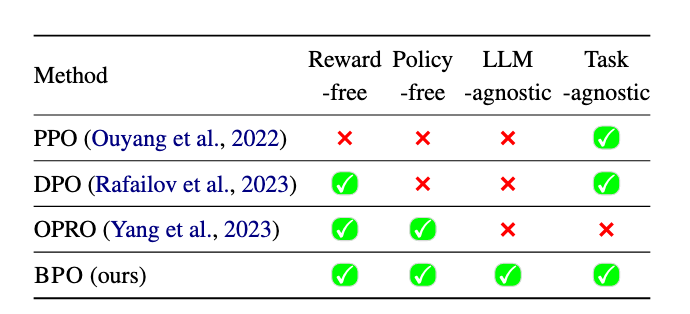 表2:与RLHF(PPO)、DPO、OPRO的比较。BPO无需训练奖励模型或策略模型,并且在应用中对任意大语言模型(LLM)或任务均具有无关性(即模型与任务无关)。
表2:与RLHF(PPO)、DPO、OPRO的比较。BPO无需训练奖励模型或策略模型,并且在应用中对任意大语言模型(LLM)或任务均具有无关性(即模型与任务无关)。
如表2所示,BPO(本文提出的方法)相较于现有对齐方法展现出若干显著优势。尽管各类方法的终极目标都是让大语言模型(LLMs)的输出契合人类偏好,但RLHF(Ouyang et al., 2022)与DPO(Rafailov et al., 2023)是通过修改LLM参数来拟合人类偏好;而BPO则从输入侧切入——优化用户提示(prompt)以使其更适配模型特性,进而提升模型输出与人类偏好的对齐度。
此外,由于BPO不改变LLM的参数,它可应用于API型模型(如通过接口调用的闭源模型);而PPO与DPO仅能用于白盒模型(需访问模型内部参数的开源模型)。与OPRO等提示工程方法相比,BPO更具通用性:OPRO需针对特定任务搜索重写提示,且不进行样本级优化——它在每个任务中对所有样本使用同一学习到的提示,易导致稳定性不足。
更进一步,PPO、DPO与OPRO仅能优化特定LLM;而BPO一旦训练完成,便具有模型无关性(model-agnostic)。如第3.1节所述,我们的目标是学习从用户提示到优化提示的通用映射(遵循人类偏好)——这一目标通过在训练数据中纳入多LLM的生成结果实现。对人类偏好的融入,使BPO的表现优于直接用LLM(如ChatGPT)进行提示优化的方式。
4 实验
为全面展示BPO的能力,我们开展了广泛的实验,涵盖多个方面,包括与黑盒模型的对齐能力、与现有反馈学习技术(DPO与PPO)的比较、监督微调(SFT)数据质量提升能力、迭代改进能力、与提示工程方法(见附录H)的比较,以及对反馈机制的消融研究。具体实现细节可参见附录C。
4.1 对齐的评估
由于全面评估一个语言模型的对齐质量仍然是一项重大挑战,在本研究中,我们采用了广泛使用的设定,即利用强大的大语言模型(LLM)来评估目标模型在指令跟随数据集上的表现。
测试数据集 Datasets 为了更准确地评估对齐质量,我们选取了多个指令数据集进行测试。
- Dolly Eval 是从 Dolly(Conover 等人,2023)数据集中随机抽取的 200 条样本组成的子集。该数据集由人工生成,涵盖八类任务。
- Vicuna Eval(Chiang 等人,2023)包含 80 道多样化的问题,涵盖 8 个类别。
- Self-Instruct Eval 是由 Wang 等人(2022)创建的人工评估数据集,包含 252 条由专家撰写的面向用户的指令,这些指令基于现实应用场景设计。
- BPO-test Eval 是我们自建数据集的一个划分,包含来自训练集构建过程中所使用的四个数据集的 200 条样本。
评估方法 已有研究(Wang 等,2023;Zheng 等,2023)表明,强大的大语言模型(LLM)可以胜任评估者的角色。遵循 Li 等人(2023)的做法,我们分别采用 GPT-4(OpenAI,2023)和 Claude(Anthropic,2023b)进行评估,并采用成对评分(pairwise scoring)的设置,以直观展现不同模型在对齐能力上的差异。GPT-4 的评分提示来自 MT-bench(Zheng 等,2023),Claude 的评分提示则来自 Alpaca Eval(Li 等,2023),相关提示内容可在附录 D 中查阅。此外,为减轻位置偏差并降低评估成本,我们在每次评估中会随机打乱各模型的回复顺序,该做法同样被 Alpaca Eval 所采用。
4.2 黑盒对齐结果
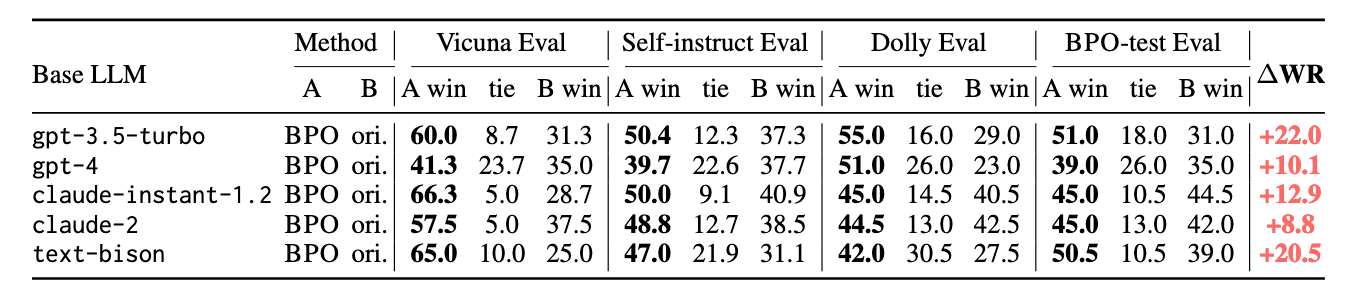 表3:由GPT-4评估的BPO对齐模型与原版大语言模型API之间的胜率对比(关于Claude-v1.3的评估结果,参见表8)。在不对大语言模型进行训练的前提下,BPO能够显著提升黑盒LLM API的对齐性能。(“ori.”表示“原始”,“WR”表示“胜率”。)
表3:由GPT-4评估的BPO对齐模型与原版大语言模型API之间的胜率对比(关于Claude-v1.3的评估结果,参见表8)。在不对大语言模型进行训练的前提下,BPO能够显著提升黑盒LLM API的对齐性能。(“ori.”表示“原始”,“WR”表示“胜率”。)
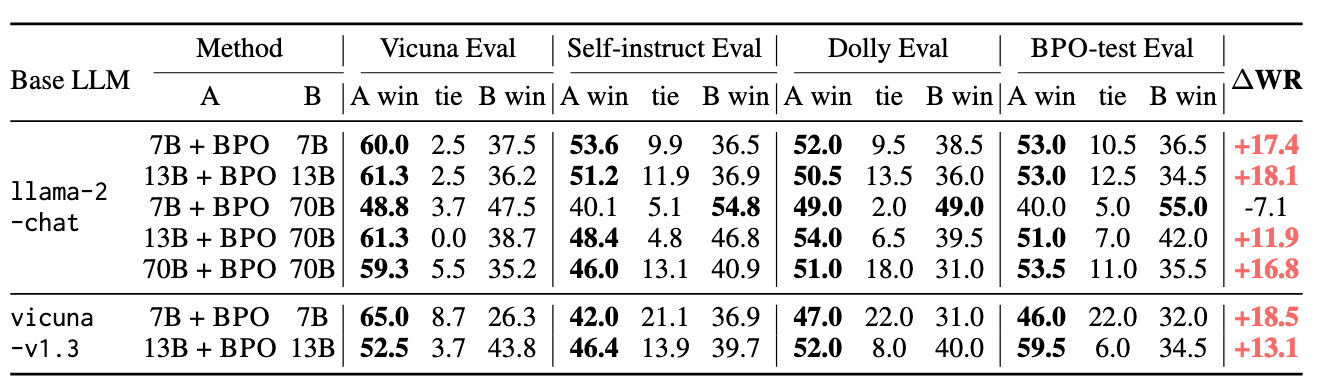 表4:由GPT-4评估的BPO对齐模型与原版Llama-2-Chat和Vicuna-v1.3模型之间的胜率对比(关于Claude-v1.3的评估结果,参见表9)。无需训练的BPO显著提升了模型的对齐性能,甚至使Llama-2-13B-Chat的表现优于Llama-2-70B-Chat。(“WR”表示“胜率”。)
表4:由GPT-4评估的BPO对齐模型与原版Llama-2-Chat和Vicuna-v1.3模型之间的胜率对比(关于Claude-v1.3的评估结果,参见表9)。无需训练的BPO显著提升了模型的对齐性能,甚至使Llama-2-13B-Chat的表现优于Llama-2-70B-Chat。(“WR”表示“胜率”。)
详细实验结果可参见表3和表4。与原始提示相比,我们的方法在使用优化提示的情况下,在所有模型、所有数据集上均取得了更高的胜率。值得注意的是,在gpt-3.5-turbo和text-bison上,平均胜率提升了约20%;而在包括gpt-4在内的多个模型中,提升幅度更是超过10%,充分证明了我们方法的优越性能。此外,在不同能力级别的模型上均实现了稳定的性能提升,涵盖从llama2-7b-chat和vicuna-7b等较小的开源模型,到gpt-4和claude-2等强大的大规模模型,突显了BPO在各种模型上的强大泛化能力。
在这四个测试集中,最显著的提升出现在VicunaEval上。在使用GPT-4进行评估的条件下,许多经过BPO对齐的模型达到了超过60%:40%的偏好比例(即胜率提升20%),部分模型甚至达到70%:30%(胜率提升40%)。这表明,BPO在开放式指令上能够实现更显著的对齐效果。BPO还能显著增强这些开放式任务中回答的全面性(见第5节)。然而,BPO的优势不仅限于此类任务。在这些评估集包含的封闭任务中,如数学、推理和编程等,BPO同样表现优异,平均胜率提升超过10%。
此外,我们还进行了扩展性实验,如图7所示。我们将不同规模的LLaMA2-Chat模型在使用我们优化指令后的表现,与原始的llama2-70b-chat模型进行对比。值得注意的是,BPO显著提升了较小模型llama2-7b-chat的性能,使其在某些数据集上能够匹敌甚至超越规模大10倍的模型。在Claude评估下,经过BPO对齐的llama2-7b-chat几乎达到了llama2-70b-chat的水平。而对于llama2-13b-chat模型,BPO使其能够大幅超越70b模型,显示出BPO在提升小模型性能方面具备超越大型模型的潜力。
4.3 RLHF 结果
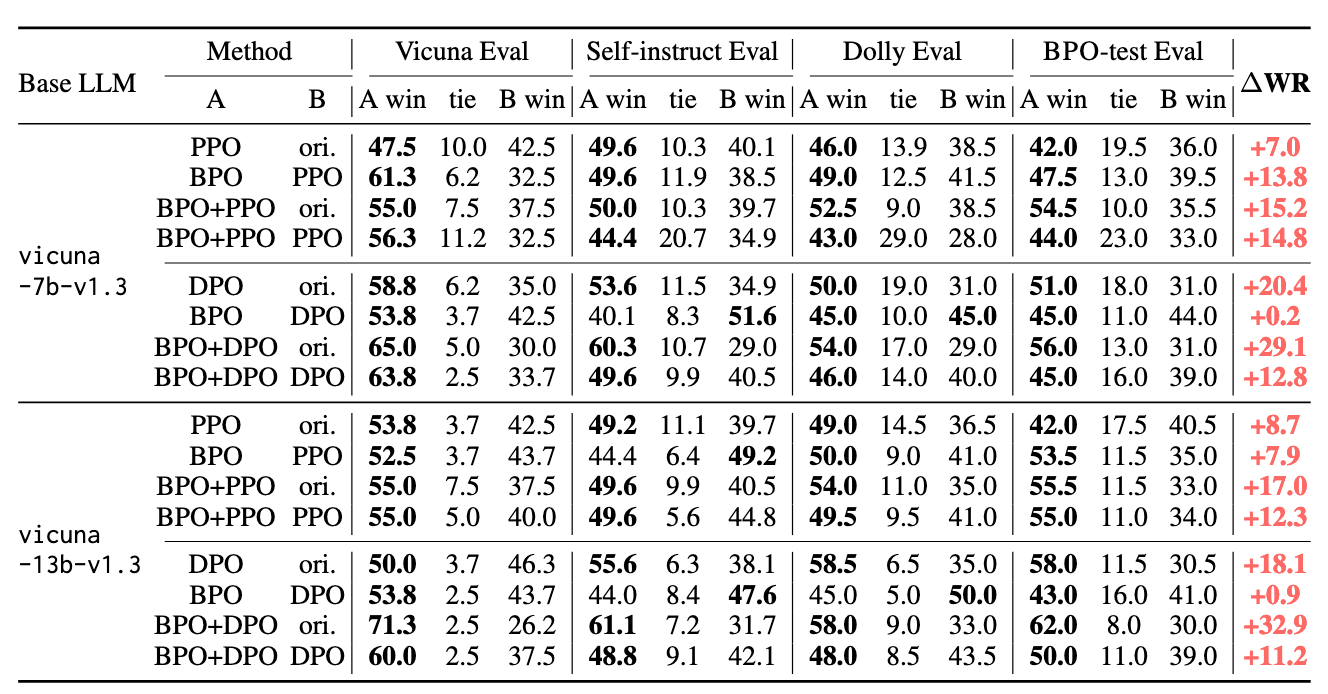 表5:由GPT-4评估的PPO、DPO与BPO对齐的Vicuna-v1.3系列大语言模型之间的胜率对比(关于Claude-v1.3的评估结果,参见表10)。BPO不仅在性能上优于PPO和DPO,而且在PPO和DPO对齐模型的基础上还能带来额外的提升。(“ori.”表示“原始”,“WR”表示“胜率”。)
表5:由GPT-4评估的PPO、DPO与BPO对齐的Vicuna-v1.3系列大语言模型之间的胜率对比(关于Claude-v1.3的评估结果,参见表10)。BPO不仅在性能上优于PPO和DPO,而且在PPO和DPO对齐模型的基础上还能带来额外的提升。(“ori.”表示“原始”,“WR”表示“胜率”。)
如表5所示,PPO、DPO和BPO均成功提升了vicuna-7b和vicuna-13b模型的表现。此外,结合BPO的SFT模型在性能上优于经PPO和DPO对齐的模型,这凸显了BPO的优势。如前所述,BPO具有模型无关性,可应用于不同能力水平的大语言模型。因此,我们进一步探究了BPO是否能够与RLHF方法结合使用,结果表明这种组合是可行的且具有积极效果:PPO和DPO在与BPO结合后均能获得显著提升。在同时采用BPO对齐和DPO训练的情况下,vicuna-7b和vicuna-13b的胜率均提高了约30%。
4.4 数据增强下的BPO
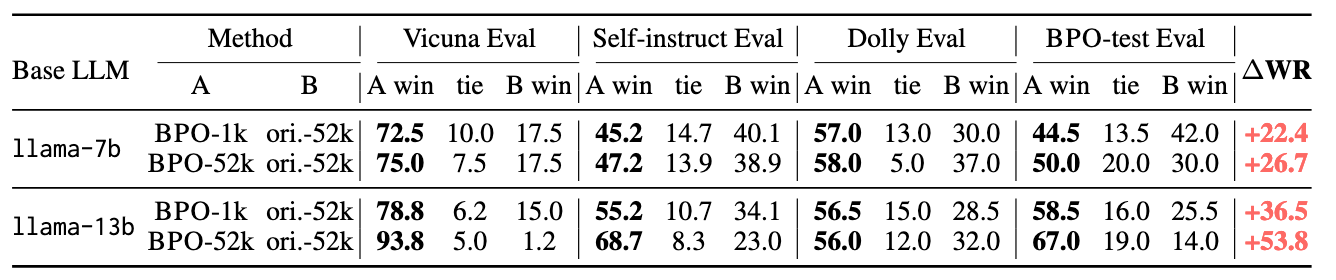 表6:由GPT-4评估的使用BPO重构数据与原始Alpaca数据集微调的Llama系列大语言模型之间的胜率对比(关于Claude-v1.3的评估结果,参见表11)。-1k表示使用随机采样的1千条数据训练模型,-52k表示使用完整数据集进行训练。(“ori.”表示“原始”,“WR”表示“胜率”。)
表6:由GPT-4评估的使用BPO重构数据与原始Alpaca数据集微调的Llama系列大语言模型之间的胜率对比(关于Claude-v1.3的评估结果,参见表11)。-1k表示使用随机采样的1千条数据训练模型,-52k表示使用完整数据集进行训练。(“ori.”表示“原始”,“WR”表示“胜率”。)
BPO还可用于生成高质量数据,即通过利用优化后的提示词引导模型生成优质回答。我们在Alpaca数据集(Taori等,2023)上验证了该方法的可行性:首先使用BPO对原始指令进行优化,然后将这些优化后的指令作为text-davinci-003的输入以生成相应回答。由此我们得到了一个精炼版的Alpaca数据集,并基于该新数据集对llama-7b和llama-13b进行了微调训练。如表6所示,实验结果表明,与使用原始Alpaca数据集训练的模型相比,新方法带来了显著的性能提升。值得关注的是,在Vicuna Eval测试中,使用5.2万条BPO重构数据训练的llama-13b模型,其对战原始数据集训练模型的胜率达到93.8%:1.2%。更进一步,即便仅使用1千条重构数据进行训练,所得模型也能超越使用5.2万条样本训练的原始模型。这些结果凸显了高质量数据的重要性,并验证了BPO在辅助生成高质量训练数据方面的有效性。
4.5 迭代式提示优化
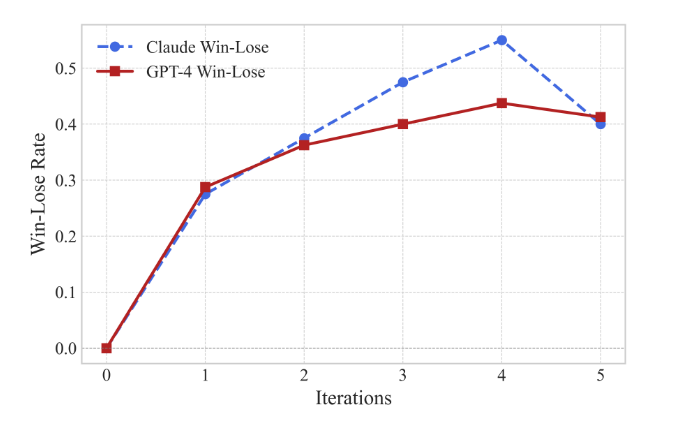 图3:由GPT-4和Claude-v1.3评分的各迭代轮次中胜率与负率的差值(第0次迭代表示原始提示)。
图3:由GPT-4和Claude-v1.3评分的各迭代轮次中胜率与负率的差值(第0次迭代表示原始提示)。
由于BPO能够优化用户提示以获得更优质的响应,一个自然的想法是:我们是否可以通过迭代方式不断改进提示,从而逐步提升大语言模型的输出质量?为此,我们在Vicuna Eval数据集上使用gpt-3.5-turbo开展了相关实验。具体而言,我们对原始指令进行五次迭代优化,并将每次优化后的提示与原始指令的胜率进行对比。如图3所示,∆WR(胜率增量)在前四次迭代中显著提升,而在第五次迭代出现小幅下降。附录G展示了每一次优化迭代后的提示案例研究。此外,我们还发现BPO具有良好的保持性——当输入提示本身已经足够优秀时,它有很大概率会保留原提示内容。我们认为,这是实现迭代增强的关键因素,因为它避免了对用户原始意图施加不合理改动。
4.6 消融实验
 表7:由GPT-4评估的BPO方法与直接使用GPT-3.5-Turbo进行提示优化(无反馈,w/o FDBK)之间的胜率对比(关于Claude-v1.3的评估结果,参见表12)。尽管BPO能大幅提升模型性能,而无反馈的直接优化仅带来微弱提升。(“ori.”表示“原始”,“WR”表示“胜率”,“FDBK”表示“反馈”。)
表7:由GPT-4评估的BPO方法与直接使用GPT-3.5-Turbo进行提示优化(无反馈,w/o FDBK)之间的胜率对比(关于Claude-v1.3的评估结果,参见表12)。尽管BPO能大幅提升模型性能,而无反馈的直接优化仅带来微弱提升。(“ori.”表示“原始”,“WR”表示“胜率”,“FDBK”表示“反馈”。)
BPO的一个关键组成部分是利用反馈来优化用户指令。为了探究反馈在BPO提示优化中所起的作用,我们开展了一项消融实验,比较基于反馈学习的优化方法(BPO)与直接使用GPT-3.5-Turbo进行提示优化的效果。如表7所示,直接优化能够提升模型性能,这验证了大语言模型具备成为优秀提示工程师的潜力。而BPO在直接优化基础上进一步带来了性能提升。结果表明,引入反馈可使大语言模型依据用户明确表达的偏好来细化提示,从而实现更有效的提示优化。
5 BPO的可解释性
与基于模型训练的对齐方法(如PPO或DPO)相比,BPO具有显著的可解释性优势,因为我 们可以直接对比优化前后的指令,从而清晰地了解BPO的优化机制。为了细致探究BPO具体优化了哪些方面,我们深入分析了500个样本,并总结了其优化过程中的一些常见模式及错误类型。
们可以直接对比优化前后的指令,从而清晰地了解BPO的优化机制。为了细致探究BPO具体优化了哪些方面,我们深入分析了500个样本,并总结了其优化过程中的一些常见模式及错误类型。
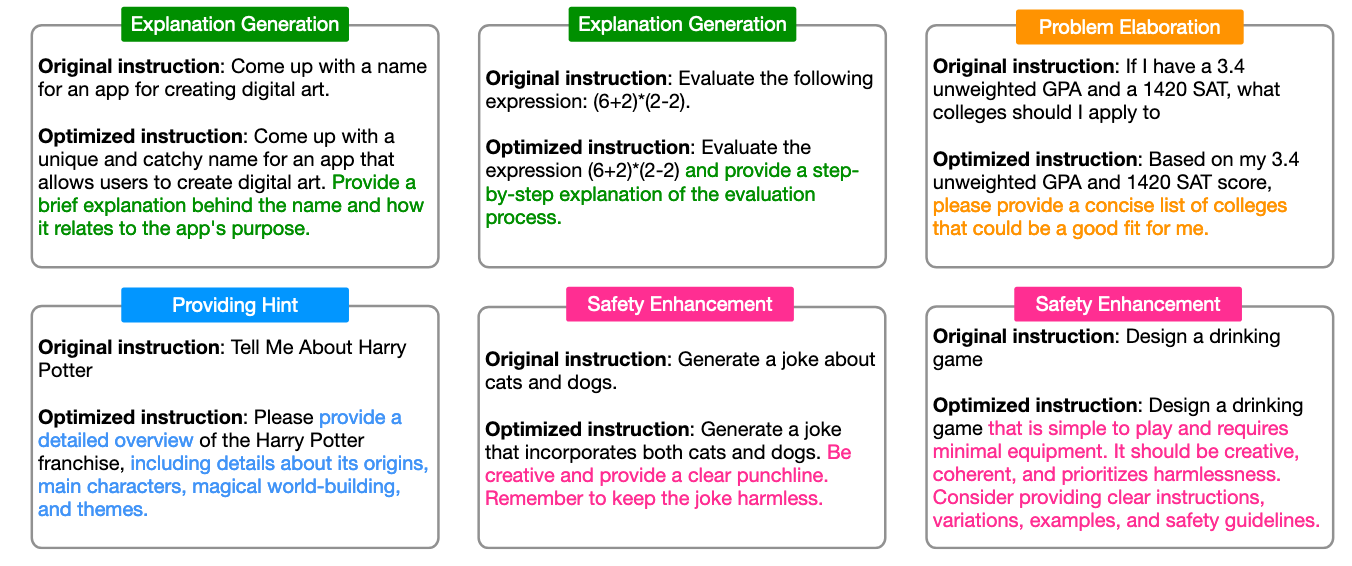 图4:BPO的优化类型及示例。由于篇幅限制,此处省略了部分示例,完整结果请参见图11。
图4:BPO的优化类型及示例。由于篇幅限制,此处省略了部分示例,完整结果请参见图11。
如图4所示,我们总结了BPO优化结果中呈现出的四种常见优化策略,包括:生成解释(绿色框)、提示细化(橙色框)、提供提示信息(蓝色框)以及安全性增强(粉色框)。需要说明的是,在BPO的输出中还观察到了其他优化策略,并且这些策略之间并非互斥关系。此处列出的示例仅为这四类策略中的典型代表。
- 生成解释:这是BPO常用的一种策略,通过指示大语言模型生成推理步骤或详细说明,帮助其形成更具逻辑性且易于理解的回答。
- 提示细化:包含多种方法,旨在帮助模型更好地理解用户意图并生成全面的回答,因为用户给出的指令往往存在表述不清、过于简略甚至含有错误的情况。
- 提供提示信息:在用户的提示中添加特定提示,例如BPO会补充需要重点阐述的关键点,或阐明相关知识,以协助模型更有条理地组织答案。
- 安全性增强:在对齐过程中至关重要。当用户输入可能引发安全问题时,BPO会强调保持无害的回应。此外,BPO能够实现可解释的安全性增强——它会将不安全的请求转化为要求模型输出相关无害建议的形式。这样既能更好地防范安全问题,又能确保回答依然具有帮助性。
错误分析详见附录I。
6 Conclusion
在本研究中,我们提出了一种黑盒对齐方法——BPO,它能够自动优化用户输入,使其更符合大语言模型的偏好,从而获得更优质的响应。借助BPO对齐,我们无需对这些模型进行额外调整即可显著提升其与人类偏好的对齐程度,即使在GPT-4和Claude-2等当前最强大的模型上也取得了显著成果。此外,大量实验表明,在Vicuna系列模型上,BPO能够达到甚至超越现有主流对齐技术的性能,并能够进一步提升这些对齐方法的效果。
我们的研究结果表明,针对大语言模型特性量身定制输入,是一条可与现有基于模型训练的对齐方案并行推进的可解释、可控对齐技术路径,并且在该方向上仍有广阔的探索空间以待深入挖掘。
限制
尽管BPO在效果和更广泛应用的潜力方面表现出色,我们仍需指出本研究的一些已知局限性,这些方面有待后续研究与努力加以改进。
需要更多的数据和训练 尽管我们已经证明,BPO能够在包括Vicuna Eval(Chiang等,2023)、Self-Instruct Eval(Wang等,2022)以及我们采样的Dolly Eval(Conover等,2023)在内的既有基准测试上有效提升对齐性能,但我们的提示偏好优化器(BPO-test Eval)目前仅基于少量现有学术反馈数据集组合得到的1.4万对优化提示进行训练。其覆盖的场景范围有限,尚未在大规模数据上进行训练。因此,当前发布的优化器在面向非常通用的使用场景时,表现可能不如预期。
对长上下文与数学相关输入的适配不足 我们还注意到,由于所采用的学术反馈数据集数量有限,提示的主题分布与长度存在不平衡问题。一方面,缺乏长上下文提示。以摘要任务为例,由于缺乏相关训练数据,我们的提示优化器倾向于改动用于摘要的指令提示以及原文本身(而原文本应保持不变)。另一方面,在数学相关问题上,目前的提示优化器似乎未能学会如何调整输入以获得更好性能。我们认为,如果在构建数据集时更关注这些主题,上述问题有望得到改善。
伦理考量
在本研究中,我们使用了多个已有的公开数据集来训练BPO。其中,OASST1(Köpf等,2023)数据集采用Apache许可证;HH-RLHF(Bai等,2022a)数据集采用MIT许可证;Chatbot Arena Conversations(Zheng等,2023)数据集与Alpaca-GPT4(Peng等,2023)数据集则采用知识共享(Creative Commons)许可证。
这些数据集中的部分指令存在安全问题。然而,在BPO的训练过程中,我们构建了优化提示对,对这些不安全指令进行了安全性增强处理,从而进一步缓解或消除了其中的安全隐患。